人とロボットの協調に向けた意図の生成と共有のモデル化

研究の背景・目的
人間同士のインタラクションにおいて、協調するために相手の行動の意図を推定することが重要と一般的に考えられる. 意図的な行動とはある目標を達成するための行動である.しかし、行動から意図を推定するメカニズムを考えるのが困難である. 神経科学の研究では人間が意図を意識する前に行動が決まったことを示した[Libet 83, Haggard 05]. また、[Decety 03]に自分の行動と相手の行動は共有な脳の回路で表現すると示している. 本研究の仮説は文脈(コンテキスト)に応じて目標を予測し、目標までの一連な行動を実行することによって意図が生み出す. そこで、自己の行動決定モデルを用いて相手の意図を予測することが可能になると考える. その意図を共有することで協調することができるようになる. そして、上記のメカニズムをモデル化し、ロボットに搭載することが本研究の目的である.
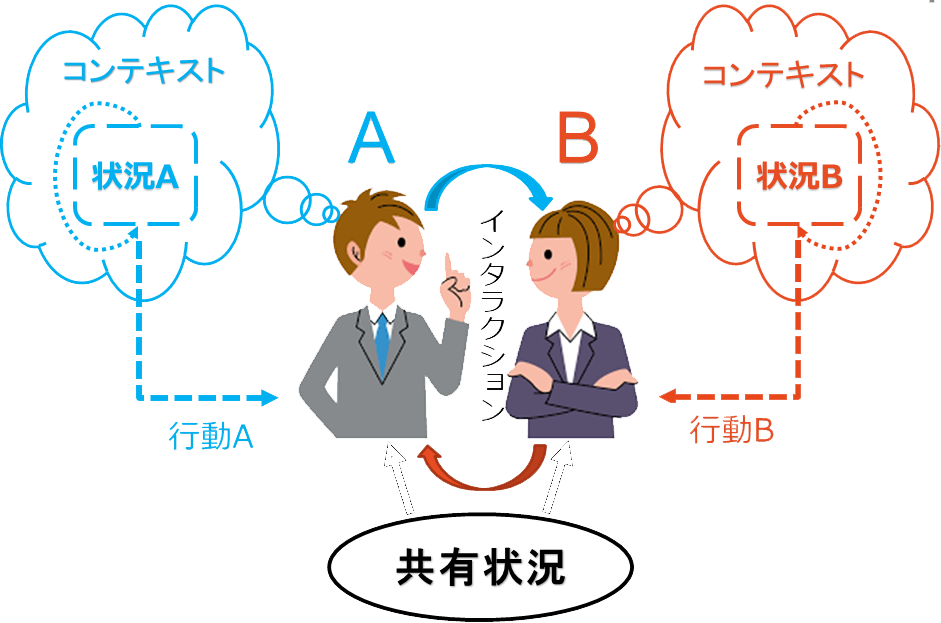
全体モデルの概要
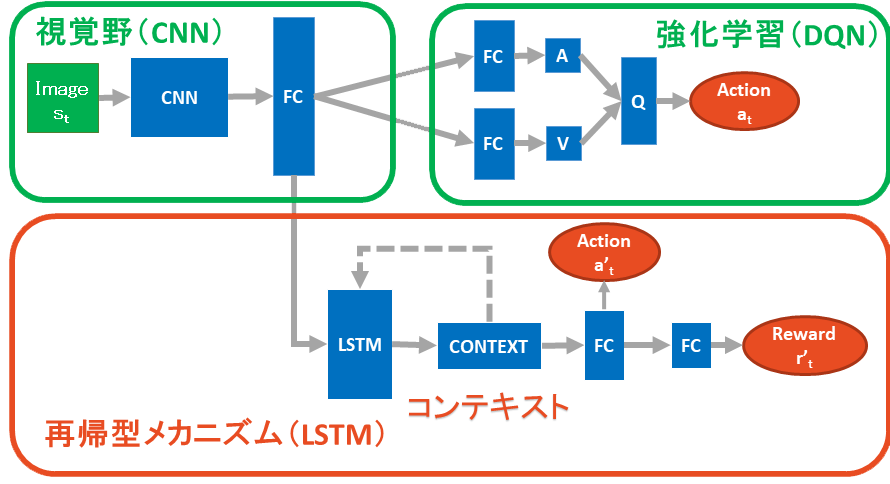 全体モデルの概要
全体モデルの概要
行動決定エージェントに対して、目標とはある種の報酬を沢山貰える望ましい特定な状況と考えられる. それを達成するために、現状から取るべき一連な行動を試行錯誤的に学習する. これを本研究で Dueling Deep Q-Network(DQN)[Zhang 16]を用いてモデル化する. また、繰り返し学習すると現状から目標までどいう行動を取ってどいう環境の変化を起こせばよいのかを覚えるようになる。 これを現状から目標までの流れ(コンテキスト)と呼ぶ。 この流れを予測することができれば、その目標に向かう行動を決めることができ、つまり意図が生成される. この過程を本研究で Long Short-term memory(LSTM)[Hochreiter 97]を用いてモデル化する. エージェント同士がインタラクションする際に外部状況が共有するので、 状況からどの目標を目指すべきなのかも共有することができる.
実験及び結果
上記提案したモデルを用いて、コンテキストから意図生成に基づく協調のメカニズムとしての有効性を検討するために、 最初にシミュレーションにて以下の積み木タスクを用いる.実験の詳細や結果などは以下に述べる。
実験概要
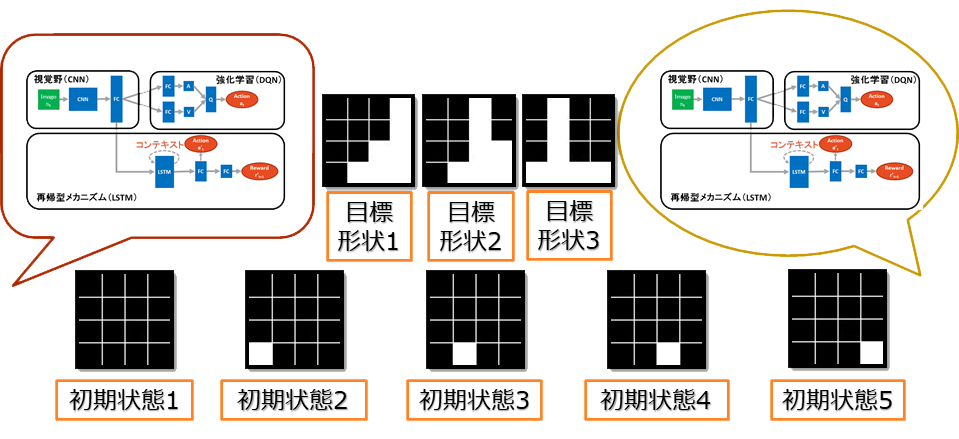
積み木タスクには右の図を示すように提案した行動決定モデルを持つ二体のエージェントは ある初期状態から交互に事前に決められた目標形状の中に一つの形状を作り上げることがタスクの目標となる. 本実験では 4x4 のボードを用い、各エージェントが取る可能な行動は 16 セルの位置に対応する 16 行動となる. 白いブロックがないセルを選択するとブロックを置くという行動になり、逆にすでにブロックがあるセルを選択するとそのブロックを取り除く行動となる. これを一つのステップとする.初期状態から目標形状を作り上げると一つのエピソードとし、タスクが終了する. 各エピソードの最大の長さを 30 とし、これを超えても目標形状が完成されない場合、タスクを終了させる.
二体で協調タスクを行う前に各エージェントは事前にすべての目標形状を作り上げることを DQN のモジュールで強化学習し、 すべての経験したエピソードを保存する.保存した経験を用いて LSTM モジュールが初期状態から 目標形状までの一連な行動と得られる報酬を予測するために学習を行う. 最後に LSTM より行動決定を行う二体のエージェントが協働でタスクを実行する.
実験の結果(その1)
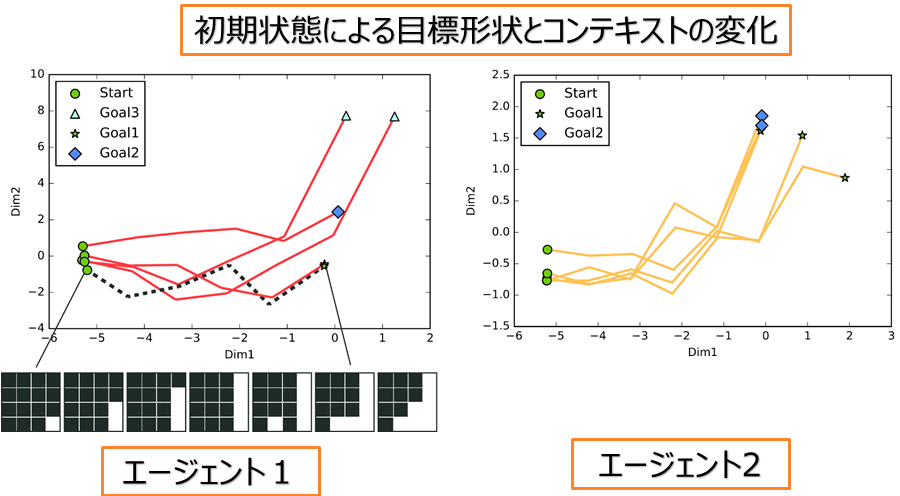
各エージェントは別々に学習したので、モデルのパラーメタが異なる. そのため、同じな状況でもそれぞれ取る行動が同じと限らない. 左の図にはこのことを示す.それぞれのエージェントの LSTM により行動決定の過程を示すために、 LSTM の出力ベクトルから PCA より二次元に圧縮し、可視化した図となる. エージェント両方が学習した初期状態のセットと目標形状のセットが同じだが、 それぞれどの初期状態でどの目標形状を作り上げるのかはそれぞれ異なることが分かる.
実験の結果(その2)
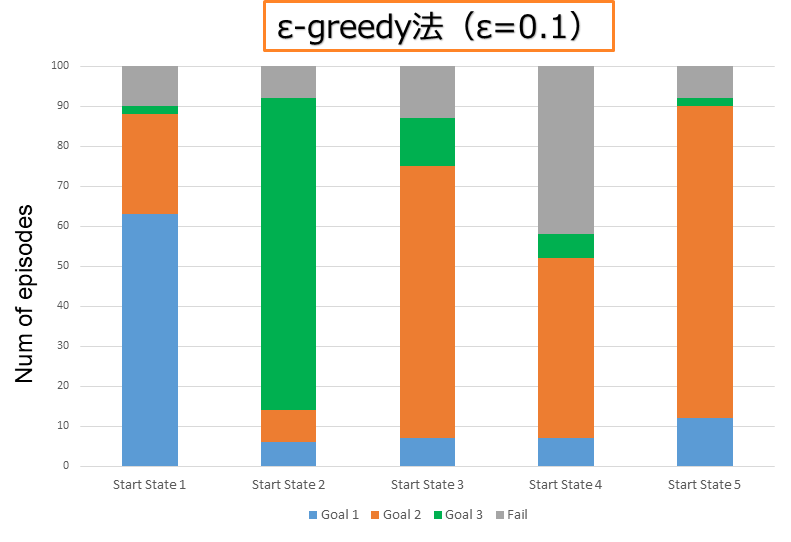
二体のエージェントが各初期状態から 100 エピソードの協働タスクを行った結果は左の図に示す. 各エージェントの行動決定において e-greedy 法(e=0.1)を用い、0.1 の確率で LSTM より出力した行動の代わりにランダムな行動を取るように設定する. これは協働する時の場面を増やす目的である.図に示すように LSTM より行動決定すると状況の変化に合わせることで 最初に異なる目標形状を目指す二体のエージェントが最終的に同じな目標形状を完成することができた. また、途中で予測通りではないランダムな行動が起きても他の目標形状に変換し、お互いに協働してタスクを成功させることもできた.
実験の結果(その3)
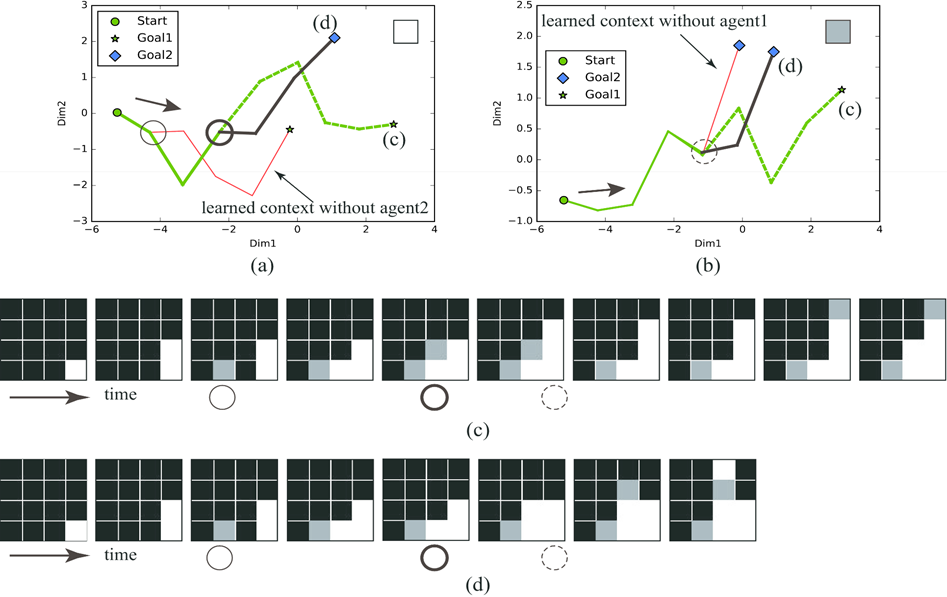
左の図には一つの初期状態から相手の行動による状況の変化に沿って二体のエージェントの行動決定の過程を示すために 二つのエピソードを取り上げて、それにおける各エージェントの LSTM の出力を可視化した. 赤い線は各エージェントが独立で学習した一連な行動を示す.そして、協働でタスクを行ったとき、相手の行動によって 自分の行動を変えて合わせる分岐点とエピソードが図の(c)、(d)に示す.
今後の課題
今後の課題として以下のことを考えている.
- より現実のタスクを検討する
- 自己行動決定モデルに基づく相手の行動を予測するメカニズムを追加する
参考文献
- [Libet 83] Libet B. et al: Time of conscious intention to act in relation to onset of cerebral activity, The unconscious initiation of a freely voluntary act. Brain 106, 623-642 (1983).
- [Haggard 05] Haggard P.: Conscious intention and motor recognition, Trends in Cognitive Sciences 9(6): 290-295 (2005).
- [Decey 03] Decety et al: Shared representations between self and other, Trends in Cognitive Sciences, 7, 527 – 533. (2003)
- [Wang 16] Z.Wang et al: Dueling Network Architectures for Deep Reinforcement Learning, arXiv, 1511.06581 (2016)
- [Hochreiter 97] S. Hochreiter et al: Long Short-term Memory, Neural Comput. 9, 8, 1735 – 1780 (1997)